Cartpole Swingup with Observational Dropout
Learning to Predict Without Looking Ahead:
World Models Without Forward Prediction
Abstract
Much of model-based reinforcement learning involves learning a model of an agent's world, and training an agent to leverage this model to perform a task more efficiently. While these models are demonstrably useful for agents, every naturally occurring model of the world of which we are aware--e.g., a brain--arose as the byproduct of competing evolutionary pressures for survival, not minimization of a supervised forward-predictive loss via gradient descent. That useful models can arise out of the messy and slow optimization process of evolution suggests that forward-predictive modeling can arise as a side-effect of optimization under the right circumstances. Crucially, this optimization process need not explicitly be a forward-predictive loss. In this work, we introduce a modification to traditional reinforcement learning which we call observational dropout, whereby we limit the agents ability to observe the real environment at each timestep. In doing so, we can coerce an agent into learning a world model to fill in the observation gaps during reinforcement learning. We show that the emerged world model, while not explicitly trained to predict the future, can help the agent learn key skills required to perform well in its environment.
Introduction
Much of the motivation of model-based reinforcement learning (RL) derives from the potential utility of learned models for downstream tasks, like prediction

We hypothesize that explicit forward prediction is not required to learn useful models of the world, and that prediction may arise as an emergent property if it is useful for an agent to perform its task. To encourage prediction to emerge, we introduce a constraint to our agent: at each timestep, the agent is only allowed to observe its environment with some probability . To cope with this constraint, we give our agent an internal model that takes as input both the previous observation and action, and it generates a new observation as an output. Crucially, the input observation to the model will be the ground truth only with probability , while the input observation will be its previously generated one with probability . The agent's policy will act on this internal observation without knowing whether it is real, or generated by its internal model. In this work, we investigate to what extent world models trained with policy gradients behave like forward predictive models, by restricting the agent's ability to observe its environment.
The above animation illustrates the world model’s prediction on the right versus the ground truth pixel observation on the left. Frames that have a red border frames indicate actual observations from the environment the agent is allowed to see. The policy is acting on the observations (real or generated) on the right.
By jointly learning both the policy and model to perform well on the given task, we can directly optimize the model without ever explicitly optimizing for forward prediction. This allows the model to focus on generating any “predictions” that are useful for the policy to perform well on the task, even if they are not realistic. The models that emerge under our constraints capture the essence of what the agent needs to see from the world. We conduct various experiments to show, under certain conditions, that the models learn to behave like imperfect forward predictors. We demonstrate that these models can be used to generate environments that do not follow the rules that govern the actual environment, but nonetheless can be used to teach the agent important skills needed in the actual environment. We also examine the role of inductive biases in the world model, and show that the architecture of the model plays a role in not only in performance, but also interpretability.
Motivation:
When a random world model is good enough
A common goal when learning a world model is to learn a perfect forward predictor. In this section, we provide intuitions for why this is not always necessary, and demonstrate how learning on random “world models” can lead to performant policies when transferred to the real world. For simplicity, we consider
the classical control task of balance cart-pole
While this unique perfectly describe the dynamics of the pole, if our objective is only to stabilize the system--not achieve perfect forward prediction--it stands to reason that we may not necessarily need to know these exact dynamics. In fact, if one solves for the linear feedback parameters that stabilize a cart-pole system with coefficient matrix (not necessarily equal to ), for a wide variety of , those same linear feedback parameters will also stabilize the “true” dynamics . Thus one successful, albeit silly strategy for solving balance cart-pole is choosing a random , finding linear feedback parameters that stabilize this , and then deploying those same feedback controls to the “real” model . We provide the details of this procedure in the Appendix.
Note that the “world model” learned in this way is almost arbitrarily wrong. It does not produce useful forward predictions, nor does it accurately estimate any of the parameters of the “real” world like the length of the pole, or the mass of the cart. Nonetheless, it can be used to produce a successful stabilizing policy. In sum, this toy problem exhibits three interesting qualities:
1. That a world model can be learned that produces a valid policy without needing a forward predictive loss.
2. That a world model need not itself be forward predictive (at all) to facilitate finding a valid policy.
3. That the inductive bias intrinsic to one's world model almost entirely controls the ease of optimization of the final policy.
Unfortunately, most real world environments are not this simple and will not lead to performant policies without ever observing the real world. Nonetheless, the underlying lesson--that a world model can be quite wrong, so long as it is wrong the in the “right” way--will be a recurring theme throughout.
Emergent world models by learning to fill in gaps
In the previous section, we outlined a strategy for finding policies without even “seeing” the real world. In this section, we relax this constraint and allow the agent to periodically switch between real observations and simulated observations generated by a world model. We call this method observational dropout, inspired by
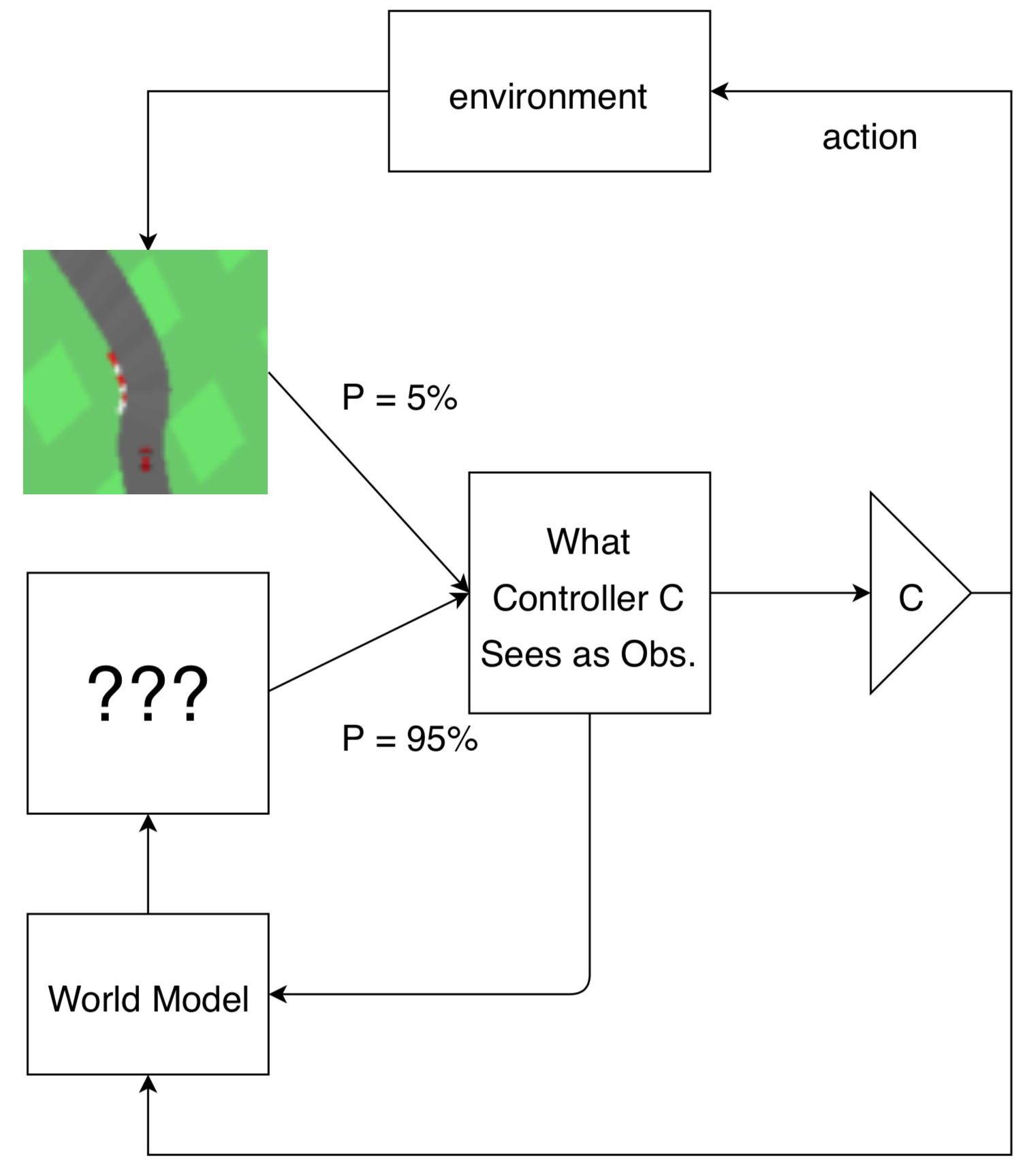
Mechanistically, this amounts to a map between a single markov decision process (MDP) into a different MDP with an augmented state space. Instead of only optimizing the agent in the real environment, with some probability, at every frame, the agent uses its internal world model to produce an observation of the world conditioned on its previous observation. When samples from the real world are used, the state of the world model is reset to the real state--effectively resynchronizing the agent's model to the real world.
To show this, consider an MDP with states , transition distribution , and reward distribution we can create a new partially observed MDP with 2 states, , consisting of both the original states, and the internal state produced by the world model. The transition function then switches between the real, and world model states with some probability :
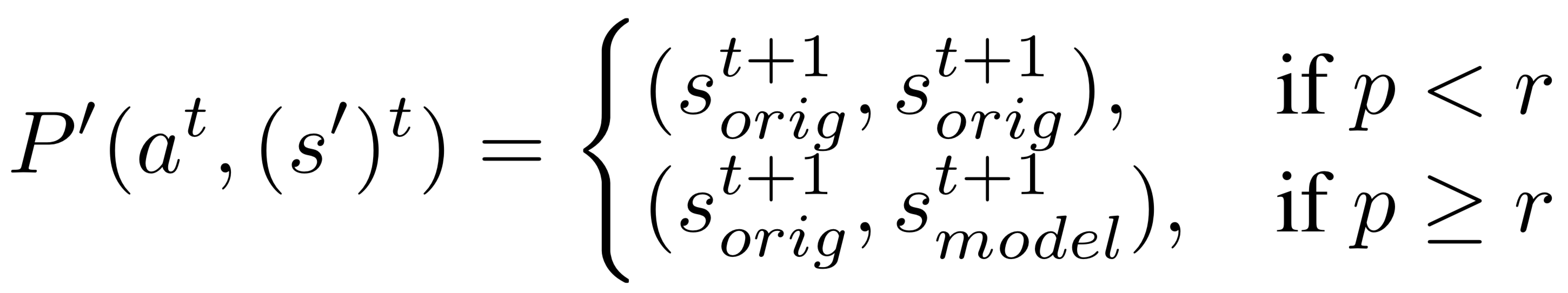
where , is the real environment transition, , is the next world model transition, , is the peek probability.
The observation space of this new partially observed MDP is always the second entry of the state tuple, .
As before, we care about performing well on the real environment thus the reward function is the same as the original environment: . Our learning task consists of training an agent, , and the world model, to maximize reward in this augmented MDP. In our work, we parameterize our world model , and our policy , as neural networks with parameters and respectively. While it's possible to optimize this objective with any reinforcement learning method
One might worry that a policy with sufficient capacity could extract useful data from a world model, even if that world model's features weren't easily interpretable. In this limit, our procedure starts looking like a strange sort of recurrent network, where the world model “learns” to extract difficult-to-interpret features (like, e.g., the hidden state of an RNN) from the world state, and then the policy is powerful enough to learn to use these features to make decisions about how to act. While this is indeed a possibility, in practice, we usually constrain the capacity of the policies we studied to be small enough that this did not occur. For a counter-example, see the fully connected world model for the grid world tasks described later.
What policies can be learned from world models emerged from observation dropout?
As the balance cart-pole task discussed earlier can be trivially solved with a wide range of parameters for a simple linear policy, we conduct experiments where we apply observational dropout on the more difficult swing up cart-pole--a task that cannot be solved with a linear policy, as it requires the agent to learn two distinct subtasks:
1. To add energy to the system when it needs to swing up the pole.
2. To remove energy to balance the pole once the pole is close to the unstable, upright equilibrium
Our setup is closely based on the environment described in
We can visualize the cart-pole experiment after training our agent inside the cart-pole swing up environment augmented with observational dropout:
As a sanity check, we can confirm that the policy that is jointly learned with the world model learns a policy that also works when observational dropout is disabled in the environment:
In the figure below, we report the performance of our agent trained in environments with various peek probabilities, . A result higher than 500 means that the agent is able to swing up and balance the cart-pole most of the time. Interestingly, the agent is still able to solve the task even when on looking at a tenth of the frames (), and even at a lower , it solves the task half of the time.

To understand the extent to which the policy, relies on the learned world model, , and to probe the dynamics learned world model, we trained a new policy entirely within learned world model and then deployed these policies back to the original environment. The results are shown in the figure below:

Qualitatively, the agent learns to swing up the pole, and balance it for a short period of time when it achieves a mean reward above 300. Below this threshold the agent typically swings the pole around continuously, or navigates off the screen. We observe that at low peek probabilities, a higher percentage of learned world models can be used to train policies that behave correctly under the actual dynamics, despite failing to completely solve the task. At higher peek probabilities, the learned dynamics model is not needed to solve the task thus is never learned.
We have compared our approach to baseline model-based approach where we explicitly train our model to predict the next observation on a dataset collected from training a model-free agent from scratch to solving the task. To our surprise, we find it interesting that our approach can produce models that outperform an explicitly learned model with the same architecture size (120 units) for cart-pole transfer task. This advantage goes away, however, if we scale up the forward predictive model width by 10x.
In the current setup, the world model is trained as part of the agent's policy, but we would also like to examine whether we can use this model to generate the environment it has trained on. To examine the kind of world our model has learned, we attempt to train a policy (from scratch) inside an open loop environment generated by this world model:
The figure above depicts a trajectory of a policy trained entirely within a learned world model deployed on the actual environment. It is interesting to note that the dynamics in the world model, , are not perfect--for instance, the optimal policy inside the world model can only swing up and balance the pole at an angle that is not perpendicular to the ground. We notice in other world models, the optimal policy learns to swing up the pole and only balance it for a short period of time, even in the self-contained world model. It should not surprise us then, that the most successful policies when deployed back to the actual environment can swing up and only balance the pole for a short while, before the pole falls down, as visualized in the following figure:
As noted earlier, the task of stabilizing the pole once it is near its target state (when , , , is near zero) is trivial, hence a policy, , jointly trained with world model, , will not require accurate predictions to keep the pole balanced. For this subtask, needs only to occasionally observe the actual world and realign its internal observation with reality. Conversely, the subtask of swinging the pole upwards and then lowering the velocities is much more challenging, hence will rely on the world model to captures the essence of the dynamics for it to accomplish the subtask. The world model only learns the difficult part of the real world, as that is all that is required of it to facilitate the policy performing well on the task.
Examining world models' inductive biases in a grid world
To illustrate the generality of our method to more varied domains, and to further emphasize the role played by inductive bias in our models, we consider an additional problem: a classic search / avoidance task in a grid world. In this problem, an agent navigates a grid environment with randomly placed apples and fires. Apples provide reward, and fires provide negative reward. The agent is allowed to move in the four cardinal directions, or to perform a no-op. For a detailed description of the grid world environment, please refer to the Appendix.
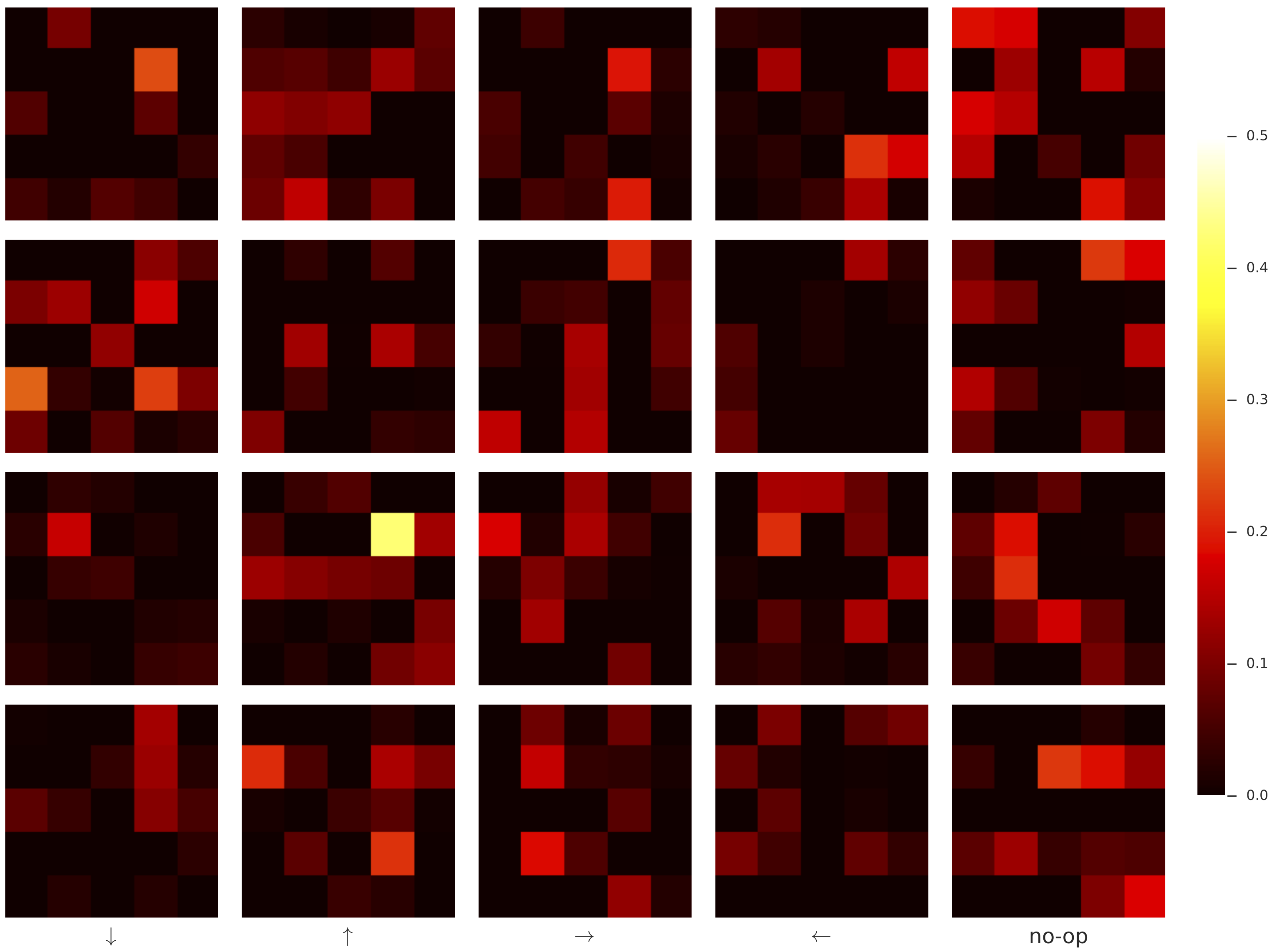
For simplicity, we considered only stateless policies and world models. While this necessarily limits the expressive capacity of our world models, the optimal forward predictive model within this class of networks is straightforward to consider: movement of the agent essentially corresponds to a bit-shift map on the world model's observation vectors. For example, for an optimal forward predictor, if an agent moves rightwards, every apple and fire within its receptive field should shift to the left. The leftmost column of observations shifts out of sight, and is forgotten--as the model is stateless--and the rightmost column of observations should be populated according to some distribution which depends on the locations of apples and fires visible to the agent, as well as the particular scheme used to populate the world with apples and fires. The figure below illustrates the receptive field of the world model:
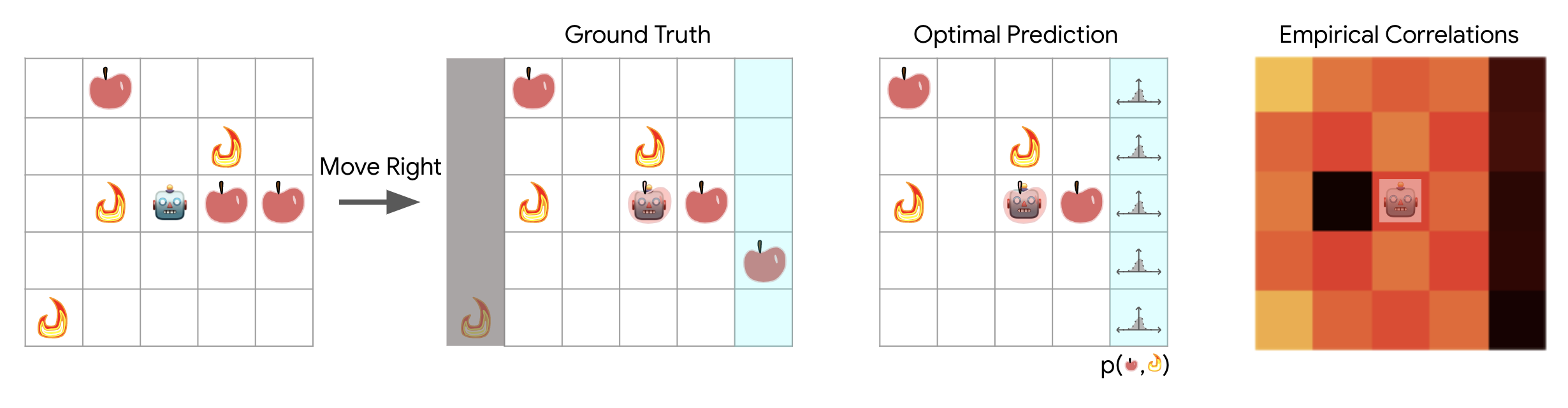
This partial observability of the world immediately handicaps the ability of the world model to perform long imagined trajectories in comparison with the previous continuous, fully observed cart-pole tasks. Nonetheless, there remains sufficient information in the world to train world models via observational dropout that are predictive.
For our numerical experiments we compared two different world model architectures: a fully connected model and a convolutional model (See Appendix for architecture details). Naively, these models are listed in increasing order of inductive bias, but decreasing order of overall capacity ( parameters for the fully connected model, learnable parameters for the convolutional model)--i.e., the fully connected architecture has the highest capacity and the least bias, whereas the convolutional model has the most bias but the least capacity. As in the cart-pole tasks, we trained the agent's policy and world model jointly, where with some probability the agent sees the ground truth observation instead of predictions from its world model. The performance of these models on the task as a function of peek probability is provided in the figure below:
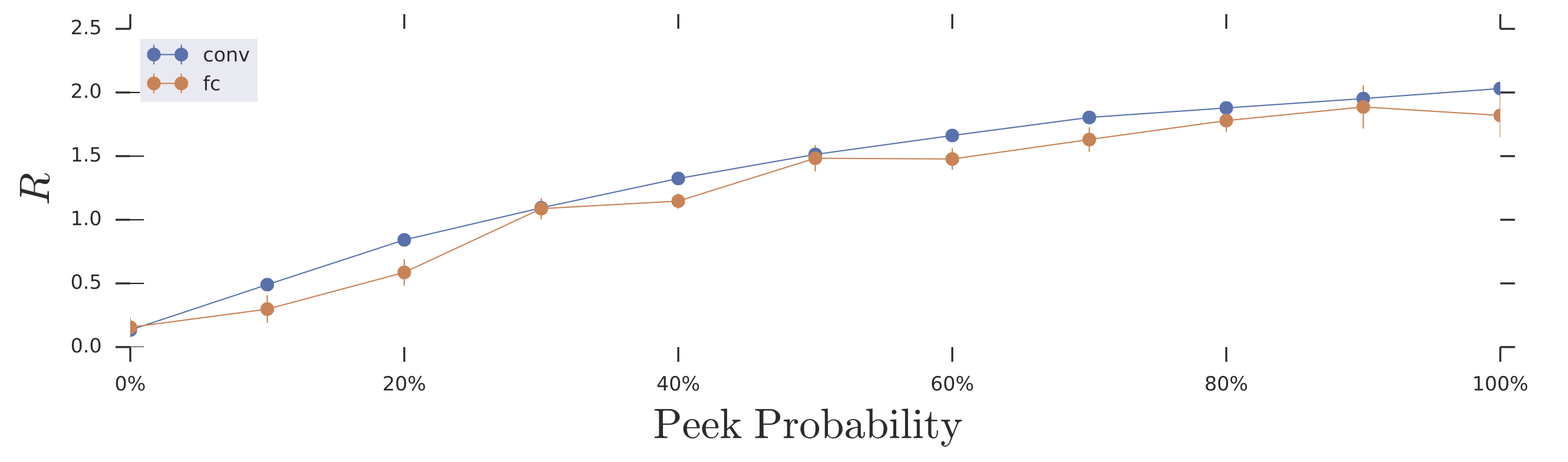
Curiously, even though the fully connected architecture has the highest overall capacity, and is capable of learning a transition map closer to the “optimal” forward predictive function for this task if taught to do so via supervised learning of a forward-predictive loss, it reliably performs worse than the convolutional architectures on the search and avoidance task. This is not entirely surprising: the convolutional architectures induce a considerably better prior over the space of world models than the fully connected architecture via their translational invariance. It is comparatively much easier for the convolutional architectures to randomly discover the right sort of transition maps.
Because the world model is not being explicitly optimized to achieve forward prediction, it doesn't often learn a predictive function for every direction. We selected a typical convolutional world model and plot its empirically averaged correlation with the ground truth next-frames in the following figure:
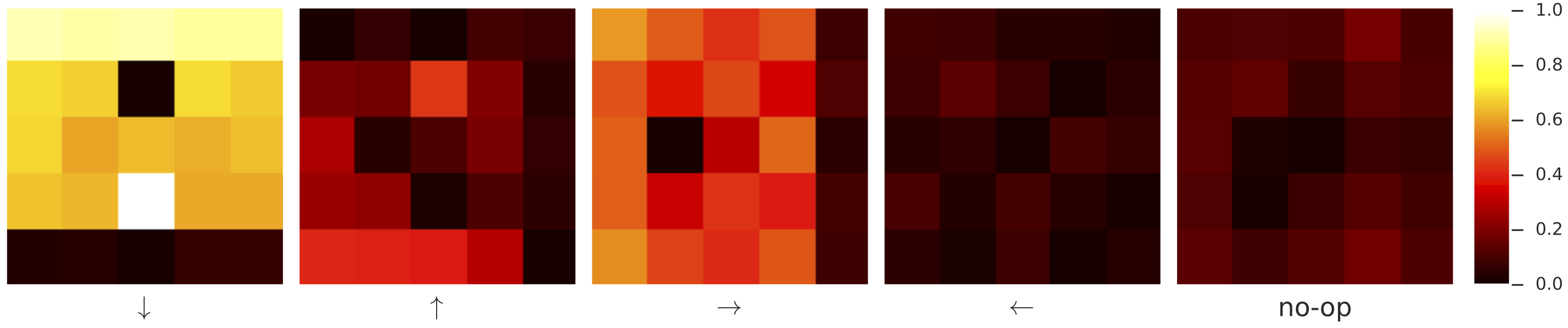
Here, the world model clearly only learns reliable transition maps for moving down and to the right, which is sufficient. Qualitatively, we found that the convolutional world models learned with peek-probability close to were “best” in that they were more likely to result in accurate transition maps--similar to the cart-pole results indicated earlier.
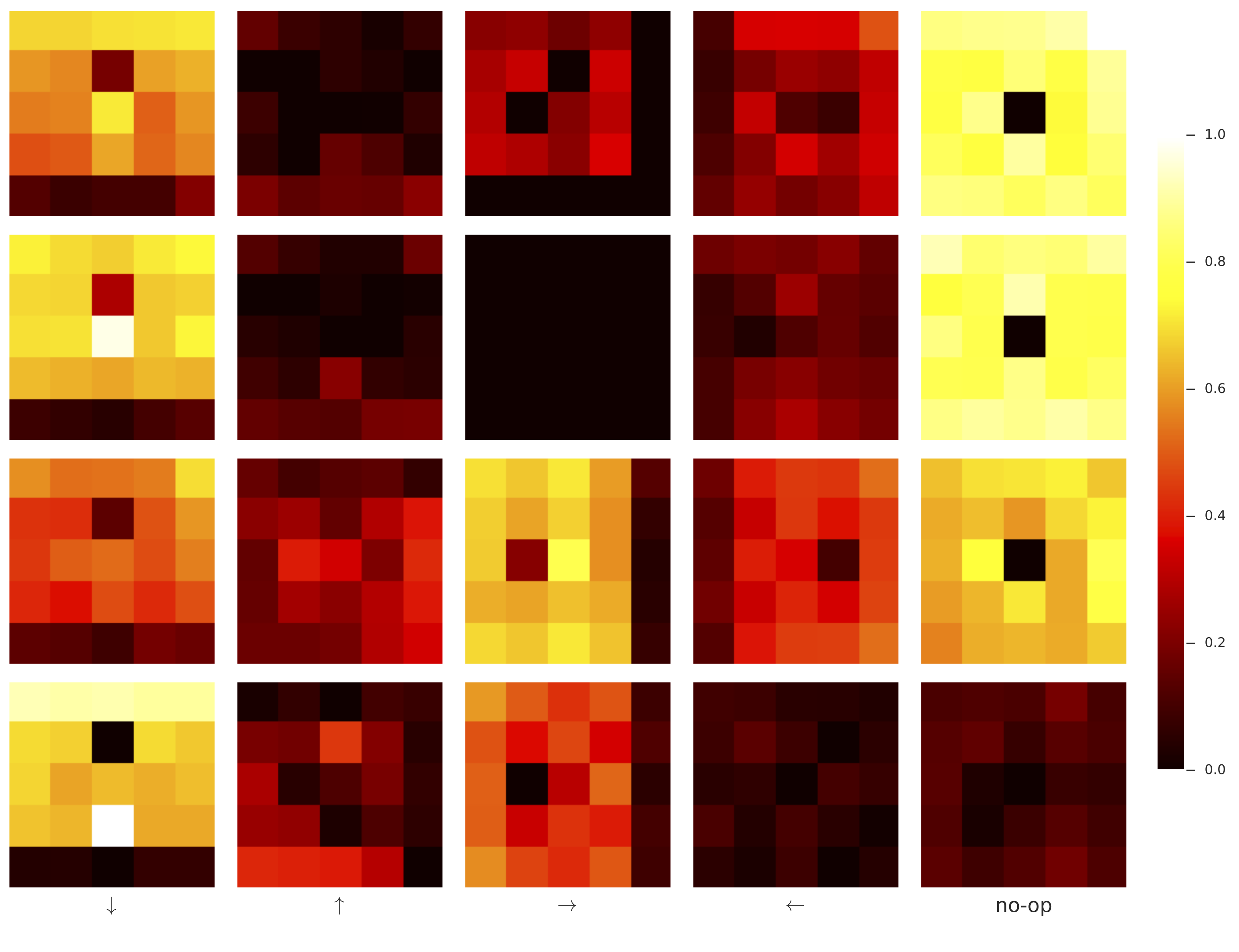
Fully connected world models, on the other hand, reliably learned completely uninterpretable transition maps. That policies could almost achieve the same performance with fully connected world models as with convolutional world model is reminiscent of a recurrent architecture that uses the (generally not-easily-interpretable) hidden state as a feature.
Car Racing: Keep your eyes off the road
In more challenging environments, observations are often expressed as high dimensional pixel images rather than state vectors. In this experiment, we apply observation dropout to learn a world model of a car racing game from pixel observations. We would like to know to what extent the world model can facilitate the policy at driving if the agent is only allowed to see the road only only a fraction of the time. We are also interested in the representations the model learns to facilitate driving, and in measuring the usefulness of its internal representation for this task.
The above animation illustrates the world model’s prediction on the right versus the ground truth pixel observation on the left. Frames that have a red border frames indicate actual observations from the environment the agent is allowed to see. The policy is acting on the observations (real or generated) on the right.
In Car Racing
To reduce the dimensionality of the pixel observations, we follow the procedure in

Our world model, , a small feed forward network with a hidden layer, outputs the change of the mean latent vector , conditioned on the previous observation (actual or predicted) and action taken (i.e ). We can use the VAE's decoder to visualize the latent vectors produced by , and compare them with the actual observations that the agent is not able to see (See figure above). We observe that our world model, while not explicitly trained to predict future frames, are still able to make meaningful action-conditioned predictions. The model also learns to predict local changes in the car's position relative to the road given the action taken, and also attempts to predict upcoming curves.
Our policy is jointly trained with world model in the car racing environment augmented with a peek probability . The agent's performance is reported in the figure below:

Qualitatively, a score above 800 means that the agent can navigate around the track, making the occasional driving error. We see that the agent is still able to perform the task when 70% of the actual observation frames are dropped out, and the world model is relied upon to fill in the observation gaps for the policy.
If the world model produces useful predictions for the policy, then its hidden representation used to produce the predictions should also be useful features to facilitate the task at hand. We can test whether the hidden units of the world model are directly useful for the task, by first freezing the weights of the world model, and then training from scratch a linear policy using only the outputs of the intermediate hidden layer of the world model as the only inputs. This feature vector extracted the hidden layer will be mapped directly to the 3 outputs controlling the car, and we can measure the performance of a linear policy using features of world models trained at various peek probabilities.

The results reported in the above figure show that world models trained at lower peek probabilities have a higher chance of learning features that are useful enough for a linear controller to achieve an average score of 800. The average performance of the linear controller peaks when using models trained with around 40%. This suggests that a world model will learn more useful representation when the policy needs to rely more on its predictions as the agent's ability to observe the environment decreases. However, a peek probability too close to zero will hinder the agent's ability to perform its task, especially in non-deterministic environments such as this one, and thus also affect the usefulness of its world model for the real world, as the agent is almost completely disconnected from reality.
Related Work
One promising reason to learn models of the world is to accelerate learning of policies by training these models.
These works obtain experience from the real environment, and fit a model directly to this data.
Some of the earliest work leverage simple model parameterizations--e.g. learnable parameters for system identification
As both predictive modeling and control improves there has been a large number of successes leveraging learned predictive models in Atari
Errors in the world model compound, and cause issues when used for control
The force driving model improvement in our work consists of black box optimization. In an effort to emulate nature, evolutionary algorithms where proposed
The boundary between what is considered model-free and model-based reinforcement learning is blurred when one can considers both the model network and controller network together as one giant policy that can be trained end-to-end with model-free methods.
Discussion
In this work, we explore world models that emerge when training with observational dropout for several reinforcement learning tasks. In particular, we've demonstrated how effective world models can emerge from the optimization of total reward. Even on these simple environments, the emerged world models do not perfectly model the world, but they facilitate policy learning well enough to solve the studied tasks.
The deficiencies of the world models learned in this way have a consistency: the cart-pole world models learned to swing up the pole, but did not have a perfect notion of equilibrium--the grid world world models could perform reliable bit-shift maps, but only in certain directions--the car racing world model tended to ignore the forward motion of the car, unless a turn was visible to the agent (or imagined). Crucially, none of these deficiencies were catastrophic enough to cripple the agent's performance. In fact, these deficiencies were, in some cases, irrelevant to the performance of the policy. We speculate that the complexity of world models could be greatly reduced if they could fully leverage this idea: that a complete model of the world is actually unnecessary for most tasks--that by identifying the important part of the world, policies could be trained significantly more quickly, or more sample efficiently.
We hope this work stimulates further exploration of both model based and model free reinforcement learning, particularly in areas where learning a perfect world model is intractable.
If you would like to discuss any issues or give feedback, please visit the GitHub repository of this page for more information.